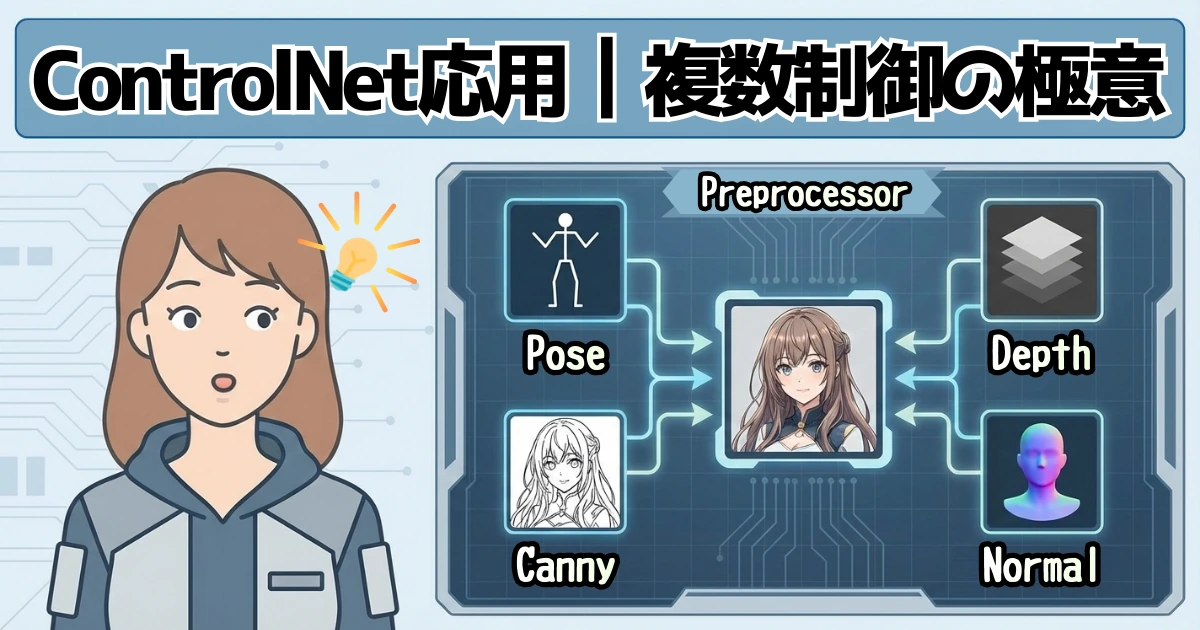
1.ControlNetを使いこなすための基本理解
ControlNetをONにしても形が安定しない。
重みを上げると破綻する。
Preprocessorを変えても違いが分からない。
こうした悩みは、決して珍しいものではありません。
原因は、設定ミスではありません。
プロンプト・LoRA・ControlNetの役割と力関係が整理できていないことにあります。
ControlNetは万能ではなく、
強くすれば良くなる仕組みでもありません。
重要なのは、
どこをControlNetに任せ、どこを任せないかです。
この章では、設定の前に
ControlNetを扱うための考え方の土台を整理します。
比較や実践を意味のあるものにするための準備です。
1-1. プロンプト・LoRA・ControlNetの関係性
ControlNetを使うと、「なぜ思い通りにならないのか?」と疑問が湧きます。
- ControlNetを強くすればすべて思い通りになるのか
- LoRAを入れているのに形や構図が変わるのはなぜか
- プロンプトを少し変えただけで結果が大きく変わるのはなぜか
すべての原因は、「生成に関わる要素の役割を混同していること」です。
■プロンプト・LoRA・ControlNetは担当範囲が違う
- プロンプト:描く内容や見た目・概念を指示(キャラクター性、雰囲気など)
- LoRA:作風や特徴を癖として上書き(顔つき、線の出方、塗り傾向)
- ControlNet:形・配置・構造を制御(ポーズ、輪郭、構図)
重要なのは「どれが強いか」ではなく「どこに作用するか」
■役割の整理
| 要素 | プロンプト | LoRA | ControlNet |
|---|---|---|---|
| 形・構造 | △ | △ | ◎ |
| 見た目・雰囲気 | ◎ | ◎ | △ |
| 構図・配置 | ○ | △ | ◎ |
| 質感・作風 | ○ | ◎ | × |
◎=得意、○=影響あり、△=間接的、×=基本的に担当外
ControlNetは見た目を作る担当ではなく、形や配置を支える裏方です。
■なぜ競合や衝突が起きるのか
生成で衝突するのは、プロンプトやLoRAがControlNetの領域に踏み込むからです。
- LoRAの体型やポーズ癖が強い → ControlNetと競合
- プロンプトに「横向き」「腕を組む」指示 → 解析画像と食い違う
結果として、形が崩れる、別人になる、ControlNetが効かないように見えることがあります。
■押さえておくべき考え方
生成結果は「強さ」ではなく「役割分担の噛み合い」で決まります。
ControlNetをうまく使うとは「強くすること」ではなく、
「任せる範囲を正しく切り出すこと」です。
生成結果は、三者の“強さ”ではなく“役割分担の噛み合い”で決まる
1-2. ControlNetの得意・不得意
ControlNetは“形”の制御に強く、“見た目”は担当外です。
■ControlNetが得意なこと
解析画像として明確に表現できる情報に忠実に従う仕組みです。
■ControlNetが苦手なこと
形として定義しづらく、意味や感覚に依存する情報は制御できません。
■得意/不得意の対比表
| 区分 | ControlNetが得意 | ControlNetが苦手 |
|---|---|---|
| 制御対象 | ポーズ・姿勢・骨格 | 表情の細かなニュアンス |
| 形状 | 輪郭・シルエット・線の位置 | 顔立ちの可愛さ・色気 |
| 構造 | 構図・配置・パーツの関係性 | キャラクター性・雰囲気 |
| 空間 | 奥行き・前後関係・立体構造 | 画風・テイスト |
| 情報の性質 | 解析画像として明示できる情報 | 意味・感覚・印象に依存する情報 |
| 向いている役割 | 「形を固定する」 | 「見た目を演出する」 |
■見た目を制御できない理由
ControlNetは意味を理解せず、線・形・濃淡・配置の解析結果だけを参照するため。
- 見た目を寄せたい → プロンプトやLoRA
- 形を固定したい → ControlNet
この切り分けが重要です。
■期待値を正しく置く
ControlNetで何でも解決しようとすると混乱します。
「形はControlNet、見た目は別手段」という前提を持つだけで、
- 効かない場面の原因
- LoRAやプロンプトに戻る判断
が明確になります。
1-3. ControlNetの効き目を決める要素
ControlNetが効かない原因は、設定項目の多さではなく、本質は2つに集約されます。
要素①:解析画像の質 ―― 何を、どこまで渡しているか
- 情報が足りない → 形や構造が固定されず効かないように見える
- 情報が多すぎる → 不要な拘束で破綻や不自然さが生じる
重要なのは、「多ければ良い」でも「細かければ正解」でもないという点です。
ControlNetは渡された解析情報に忠実に従うため、不要な情報はノイズになります。
要素②:寄せ具合 ―― どこまで従わせるか
- 強すぎる → 自由度が失われ、表現が固くなる・破綻しやすくなる
- 弱すぎる → 形が安定せず、ControlNetの意味が薄れる
ここでも大切なのは、「最大にすれば良いわけではない」という考え方です。
解析画像の情報量と寄せ具合はセットで考える必要があります。
■ControlNetは「2つの軸」で考える
- 解析画像に含まれる情報量
- どれだけ従わせるか
この2軸で挙動を理解すると、「効かない/破綻」の原因を感覚ではなく構造で判断できます。
■1章まとめ
2.Preprocessor別の特徴を知る:解析画像の違い
ControlNetの効き具合を決めるのは、設定や微調整ではなく「どんな解析画像を渡すか」です。
- 第1章で示した「解析画像 × 寄せ具合」の2軸のうち、ここでは解析画像そのものに注目
- Preprocessorが変わると、渡される情報も線・点・面などまったく異なる
- 何が残り、何が捨てられるかを見極めることが重要
出力された解析画像を観察することで、次章の比較結果も自然に理解できるようになります。
2-1. 輪郭系Preprocessor
輪郭系Preprocessorは「形をどこまで固定するか」を決める基本的なControlNet入力です。
同じ元画像から出力された解析画像を並べ、線の性質・残る情報・捨てられる情報の違いを見ていきます。
・元画像

■Canny Edge

- 写真のエッジを機械的に検出
- 細かいディテールや背景の輪郭も拾いやすい
- 線はシャープで情報量が多い
「形を強く固定したい」場合に向く一方、不要な線まで渡しやすいのが特徴
■Lineart(Standard)

- イラスト・漫画向けに最適化された輪郭抽出
- 人物や服など「意味のある輪郭」を優先して抽出
- 線は整理され、背景や細かいノイズは省かれやすい
「人物の形やポーズを自然に固定したい」場合に向く一方、立体の向きや奥行きまでは保証しないのが特徴
■HED Soft-Edge Lines

- 人が認識する「意味のある輪郭」に近い抽出
- Cannyより線が柔らかく、ノイズが減る
- 面の境界や重要な輪郭が残りやすい
形を保ちつつ、自由度も残したい場合の中間的な位置づけ
■M-LSD Lines

- 直線構造を中心に抽出
- 建物・床・フレームなどの構造が強調される
- 曲線や細部は大胆に省略される
構図や空間構造を固定したいときに力を発揮
■Scribble Lines

- 極端に情報量が少ないラフな線
- 細部や正確な輪郭はほぼ残らない
- 配置や大まかな形だけを伝える
「この辺にこれがある」程度の指示に向いた解析画像
■解析画像チェックポイント
輪郭系Preprocessorを比較するときは、
次の3点に注目すると違いが見えやすくなります。
- 線の太さ・密度
→ どこまで形を縛るか - 残る部分/省略される部分
→ モデルに委ねる余白 - ノイズの入り方
→ 意図しない制御の可能性
■輪郭系Preprocessorは「強弱の幅」を選ぶもの
重要なのは、
どれが優れているかではありません。
輪郭系Preprocessorはすべて、
「形を伝える」という役割を持ちながら、
という 制御の幅 を持っています。
2-2. 人体・ポーズ系Preprocessor
人体・ポーズ系Preprocessorは「見た目」ではなく骨格・関節・配置など人の構造をControlNetに渡します。
輪郭系が外側の形を制御するのに対し、ポーズ系は生成結果の“芯”を固定します。
・元画像

■OpenPose Pose
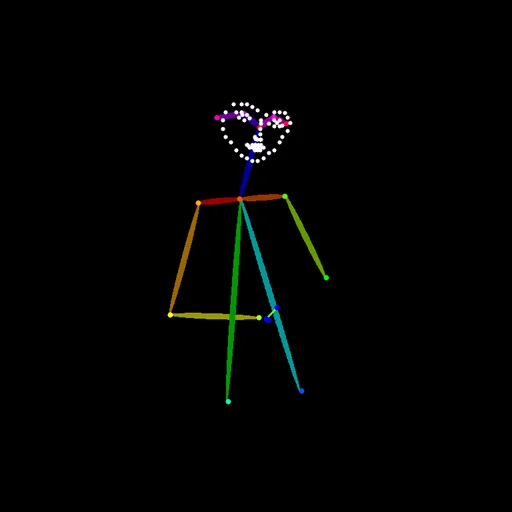
- 頭・胴体・腕・脚の骨格を検出
- 関節点と接続線のみで構成
- 表情・服装・体型情報は含まれない
「立ち姿」「手足の向き」「全身バランス」をかなり強く固定できる解析画像
■DWPose Estimator
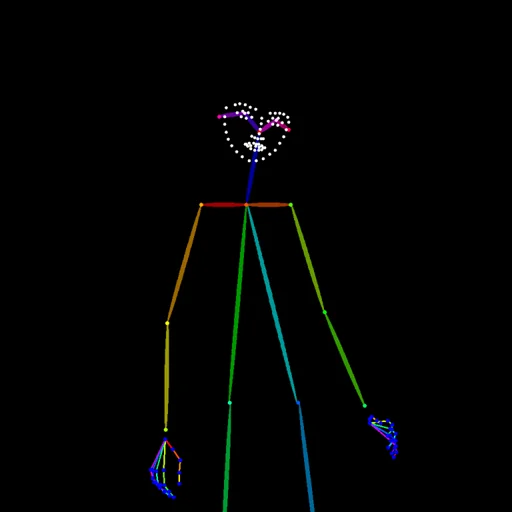
- OpenPoseより検出精度が高いケースが多い
- 手指・細かい関節まで拾えることがある
- ポーズの破綻が起きにくい
ポーズを厳密に再現したい場合や、複雑な姿勢・手の表現が必要なときに有効
■人体・ポーズ系が強力な理由
ポーズ系Preprocessorが他と決定的に違う点は、
シルエットや線ではなく「構造」を渡していることです。
- 輪郭系 → 外形・線・境界を渡す
- ポーズ系 → 骨格・関節・配置そのものを渡す
プロンプトやLoRAで姿勢を指定しても崩れる場合、最も直接的に効くControlNetです。
■制御できないもの
- 表情・体型・服装・デザイン情報は含まれず、見た目はほぼ保証されません
- 「ポーズは正しいが別人になる」「雰囲気は変わるが立ち姿は固定される」のは正常挙動
■単体完結ではない
このPreprocessorは非常に強力ですが、
多くの場合は 他のControlNetと組み合わせて使う前提になります。
- Pose × Canny
- Pose × Depth
- Pose × Lineart
といった構成で、
「骨格は固定しつつ、形や雰囲気は別で制御する」
という考え方が、後半の章で重要になってきます。
2-3. 奥行き・立体系Preprocessor
奥行き・立体を扱うPreprocessorは、
線でもポーズでもなく、「空間そのもの」をControlNetに渡します。
『どこが近く、どこが遠いか』
同一元画像から生成されたDepth解析画像を比較し、
奥行き情報の持ち方・粗さ・安定性の違いを見ます。
・元画像

■Depth Anything

- 明暗で距離を表現するDepthマップ
- 全体的に安定した奥行き推定
- 人物・背景をまとめて捉える傾向
「全体構図を崩さずに生成したい」場合に使いやすいDepth
■Zoe Depth Anything

- Depth Anythingをベースにした高精度版
- 奥行きのグラデーションが滑らか
- 前景と背景の分離が比較的はっきりする
背景保持や空間表現を重視したい場合向き
■MiDaS Depth Map
※注意※
MiDaS Depth Map は、現時点では Torch 2.6.0 が必要であり、
Windows環境では正常に動作しない場合があります。
本記事では「Depth表現の特徴理解」を目的として紹介しています。
- コントラストが強めのDepth表現
- 面ごとの奥行き差がはっきり出やすい
- 細部よりも大きな構造を優先
建物・室内・大きな構造物との相性が良い傾向
■LeReS Depth Map

- 局所的な奥行き表現に強い
- 前景・中景・背景の分離が明確
- シーンによってはやや癖が出る
奥行きの強調や立体感をはっきり出したい場合に有効
■輪郭系との決定的な違い
Depth系には線がほとんどありませんが、人物と背景の距離、建物の奥行き、カメラ位置といった空間構造は強く維持されます。
これは「線で形を固定する」のではなく、「面で空間を固定している」ためです。
■奥行き系が影響するポイント
- 背景や空間構造を保ちたい
- 建築・室内・街並みを崩したくない
- カメラアングルやパース感を維持したい
一方で、輪郭・キャラデザイン・表情などはほぼ制御しません。
■奥行きPreprocessorの特徴
Depth系は見た目を寄せるというより、生成結果を破綻しにくくする方向に働くPreprocessorです。
2-4. 解析画像の情報量と生成結果
輪郭・ポーズ・奥行きの違いは、突き詰めると解析画像が持つ情報量の差に集約できます。
Preprocessorの違いは「何を渡すか」ではなく「どれだけ渡すか」として整理できます。
・元画像

■情報量が少ない解析画像の特徴

- 含まれる情報が限定的、線や構造が少ない
- モデルの解釈に委ねる余白が大きい
- 自由度が高く、作風が出やすい
- 反面、構図や形は崩れやすい
「ControlNetで縛っているつもりでも、実はかなり自由」な状態
■情報量が多い解析画像の特徴

- 線・点・面が多く、配置や空間構造が明確
- 解釈の余地が少ない
- 構図が安定し、破綻しにくい
- その代わり変化しにくい
「生成AIに任せる範囲が狭くなる」状態
■Preprocessorが決めているのは情報量
- Preprocessor → 解析情報量
- Strength → 寄せ具合
Preprocessorを選んだ時点で、
どれくらい縛れるかの上限はほぼ決まります。
■情報量の段階イメージ
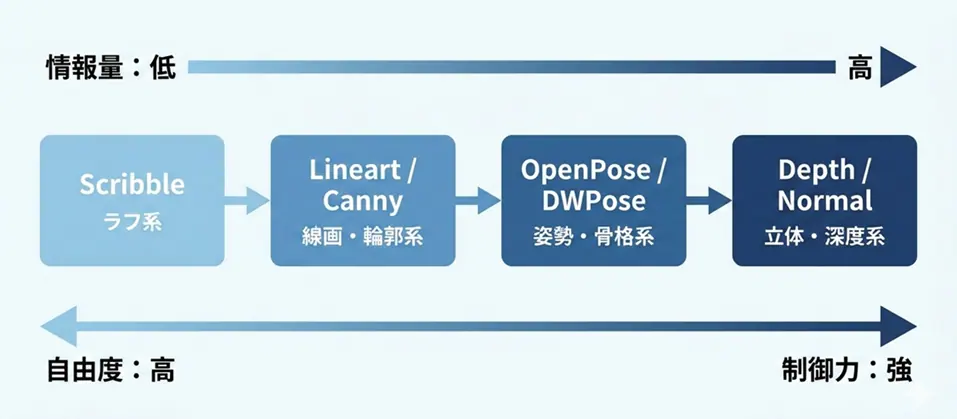
| Preprocessor | キャプション例 |
|---|---|
| Scribble | 構図のヒントだけ |
| Lineart / Canny | 輪郭を固定 |
| OpenPose / DWPose | 構造(骨格)を固定 |
| Depth / Normal | 空間・配置を固定 |
※Normal系は面の向きを解析し、立体構造を強く拘束します。
■2章まとめ
Preprocessorは効果を選ぶものではなく、解析情報の性質と量を選ぶものです。
見るべきなのは生成結果ではなく、その前段階の解析画像です。
3.実践比較①:同一画像×Preprocessor違い
この章では、同じ元画像・同じ設定で、Preprocessorだけを変更して生成結果を比較します。
ポイントは正解探しではなく、解析画像の違いが結果にどう反映されるかを見ることです。
結果と解析画像の対応関係から、「なぜこうなったか」を読み解きます。
3-1. 人物立ち絵×Preprocessor比較
人物の立ち絵は、ポーズ・構図・背景を同時に含むため、Preprocessorの違いが最も分かりやすく表れる題材です。
ここでは、違いが生成結果にどう現れるかを確認します。
■実験条件
変更するのは Preprocessorのみ です。
- 元画像:固定(同一人物・同一ポーズ)
- モデル/Seed/プロンプト:固定
- プロンプト:(masterpiece:1.2), high quality illustration, 1girl
- ネガティブプロンプト:(low quality:1.2), (worst quality:1.2), (bad anatomy:1.2)
- ControlNet strength:固定
- 使用Preprocessor:Canny / OpenPose / Depth
ControlNetの解説でよく使われる「weight」とは、「ControlNetを適用」ノードの strength を指します。本記事では、UI表記に合わせて strength で統一します。
・元画像

■解析画像比較
生成結果を見る前に、解析画像を横並びで確認します。

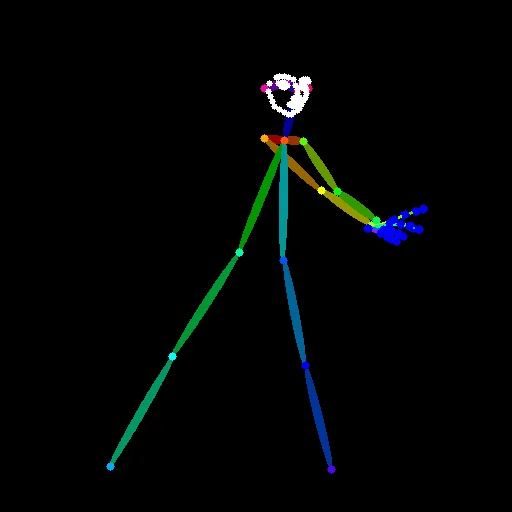

Canny
OpenPose
Depth
見るべきポイントはただ一つです。
何が残り、何が捨てられているか
Preprocessorごとに、渡している情報の種類と量が大きく異なります。
■生成結果比較
次に、各解析画像を使った生成結果を並べます。



Canny
OpenPose
Depth
※この段階では、成功・失敗の判断は不要
■まずは結果をそのまま見る
注目するのは次の点です。
- ポーズがどこまで固定されているか
- 輪郭は守られているか
- 立体感や背景はどう変わったか
「こう変わるのか」と感じられれば十分です。
なぜそうなったのか。
どの情報が効いて、どの情報が失われたのか。
3-2. 何が変わった?3つの観点で整理
前セクションの結果を、印象ではなく 構造として理解するために整理します。
見る軸を絞ることで、Preprocessor差が明確になります。
■観察軸はこの3点だけ
- 輪郭:形はどこまで固定されたか
- 立体感:奥行き・面の情報はどう扱われたか
- 背景保持:構図や配置はどれだけ維持されたか
この3軸で見ると、差が自然に浮かび上がります。
■観点①:輪郭 ―「線がある=安定」ではない
Canny や Lineart では、シルエットや境界線が明確に残ります。


Canny
Lineart
一方で、
- 線がない部分は、モデルの解釈に任される
- 立体の“向き”や“厚み”は保証されない
輪郭=完全固定ではありません。
■観点②:立体感 ― 線がなくても崩れない理由
Depth系では輪郭線がほとんどありません。
それでも、体の向きや前後関係は安定します。


Depth解析画像
Depth生成画像
これは、線ではなく
面と奥行きの情報を渡しているためです。
- 手前/奥
- 体の傾き
- 背景との距離感
こうした情報が、線なしでも構造を支えています。
■観点③:背景保持 ― なぜ構図が崩れにくいのか
Depth系では、背景や配置が比較的維持されます。
背景が模様ではなく、空間上の位置関係として扱われるためです。
構図の安定は偶然ではありません。



Canny
OpenPose
Depth
前セクションと同じ生成結果を使用しています。ここでは「背景と構図」に注目してください。
■小まとめ:違いの正体は「情報の種類」
結果の差は設定の巧拙ではありません。
渡した解析情報の 種類と量の違いです。
Preprocessorは、生成結果を直接操作しているのではなく、
モデルに渡す“材料”を変えている にすぎません。
3-3. 強すぎる/弱すぎる制御例
このセクションでは、Preprocessorは固定し、
ControlNetの寄せ具合(strength)だけを変えて比較します。
「どれだけ従わせるか」が結果にどう影響するかを見るためです。
■実験条件
- 元画像/モデル/Seed/プロンプト:固定
- プロンプト:(masterpiece:1.2), high quality illustration, 1girl
- ネガティブプロンプト:(low quality:1.2), (bad anatomy:1.2)
- Preprocessor:固定(Canny Edge)
- 変更点:ControlNet strengthのみ
原因を明確にするため、他は触りません。
・元画像

■弱すぎる例:寄せているはずなのに効かない
strengthを低くする(=0.2)

- 元画像にあまり寄らない
- ポーズや構造が曖昧になる
解析画像は渡していても、モデルの自由度が勝っている状態です。
■強すぎる例:固定しすぎて破綻する
strengthを高くする(=1.5)

- 形は強く固定される
- 歪みや質感の破綻が出やすい
これは、解析情報に過剰に従わせている状態です。
「思い通りに固定したい」という意図が、
かえって不自然さを生んでいます。
■適正値は情報量とのバランス
正解のstrengthは存在しません。
適正かどうかは、
- 解析画像の情報量
- 何をどこまで固定したいか
この組み合わせで決まります。
同じ数値でも、
- 情報量が少ない解析画像
- 情報量が多い解析画像
では、意味がまったく変わります。
■小まとめ:問題は「寄せ具合」
どちらも設定選択の結果です。
Preprocessorではなく、寄せ具合の設計が鍵になります。
3-4. 破綻を生む解析しすぎ問題
全部入れれば最強?
Canny・Pose・Depthを全部使えば完璧に制御できそうに見えますが、実は多くの人が一度は通る誤解です。ここでは「全部入り」が破綻しやすい理由を見ます。
■よくある“全部入り”構成例
まずは、実際によく見かける構成です。
- Canny(輪郭)
- OpenPose(ポーズ)
- Depth(奥行き)
・Canny + OpenPose + Depth を同時に使った構成図
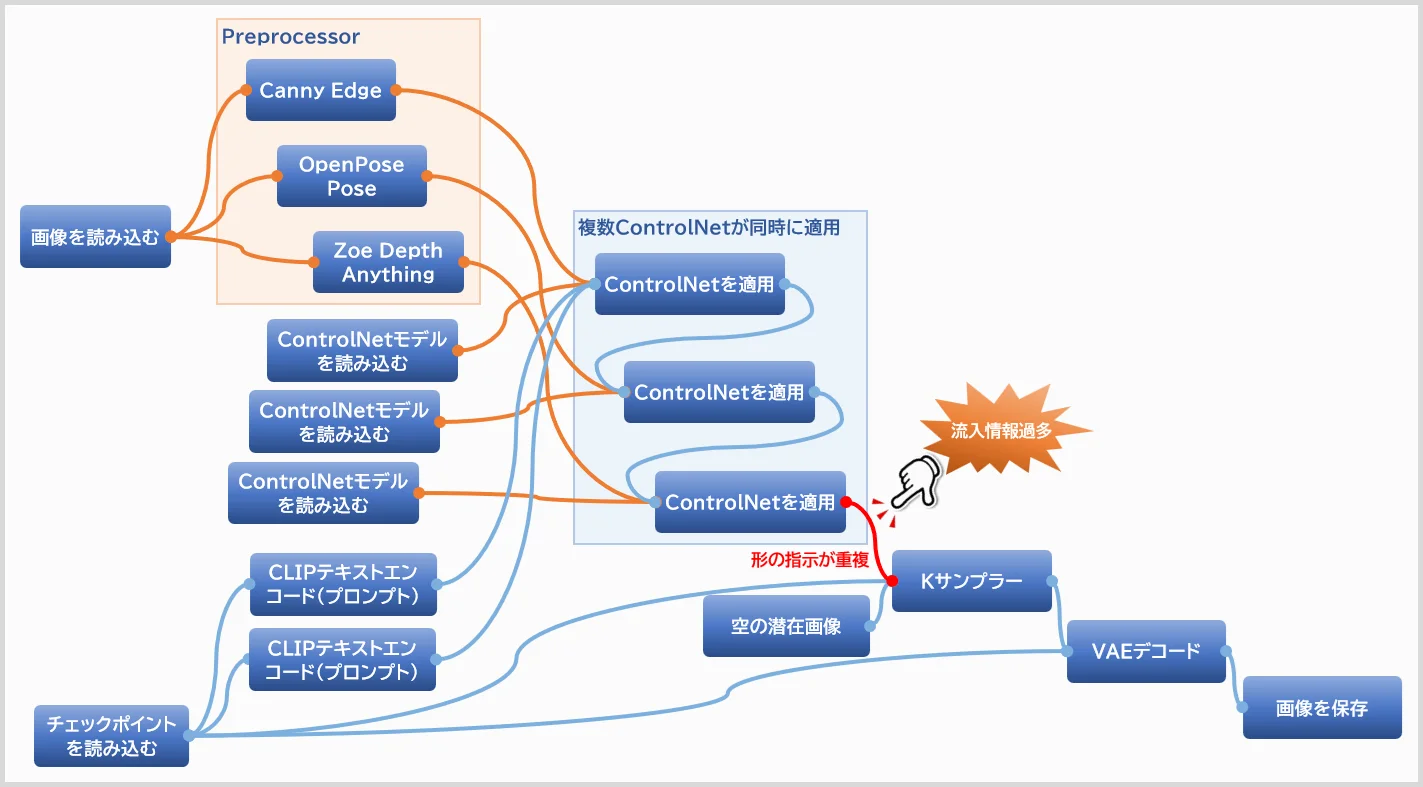
・Canny + OpenPose + Depth を同時に使ったワークフローキャプチャ
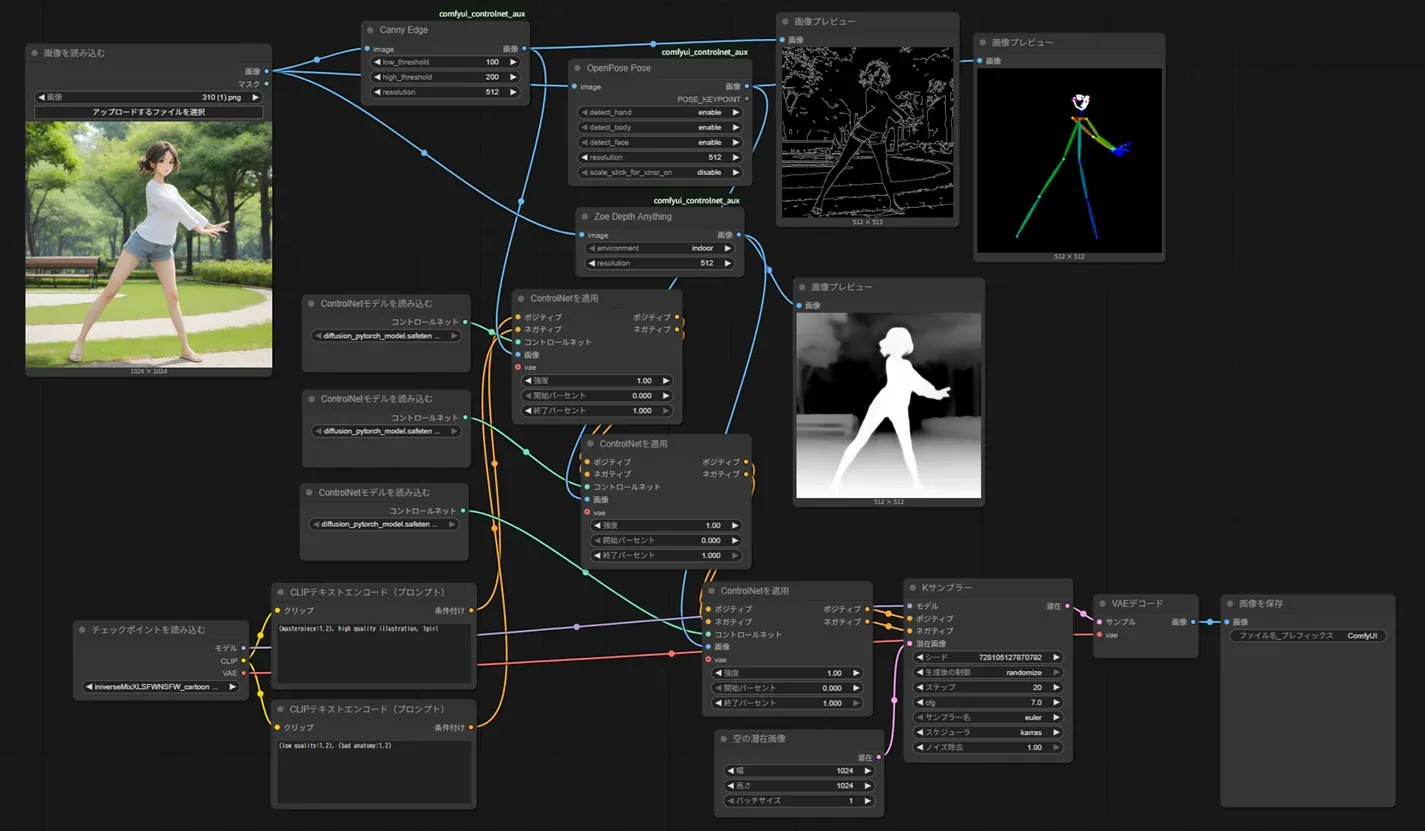
一見「形・ポーズ・奥行き」を完全指定できそうに見えます。
■解析画像を並べると分かること

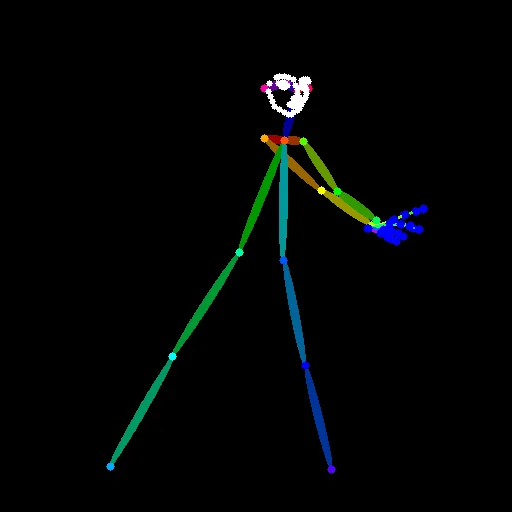

- 画面のほぼ全域が指示で埋まる
- それぞれが別の観点から命令している
情報量が多い=親切ではなく、「指示が密集」した状態
■実際の生成結果:なぜかうまくいかない



- 形は合っているのに不自然
- ポーズは守っているが硬い
- 全体の意図がぼやける
これは偶然の失敗ではなく、構造的に起きる現象です。
■なぜ破綻するのか
- 情報が多すぎて競合する
- モデルの解釈余地が消える
ControlNetは魔法ではなく「与えられた条件の中で最善を探す仕組み」
条件が多すぎると、最善が見つからなくなります。
■問題は「どれを使うか」ではない
Canny・Pose・Depthの良し悪しではなく、問題はただ一つ。
一度に渡す情報が多すぎる
■3章まとめ
4.実践比較②:解析画像の調整で結果を変える
同じPreprocessorでも、解析画像の作り方で結果は大きく変わります。
トリミングや線の強さなど、前段の調整が生成にどう影響するかを見ていきます。
目的は正解探しではなく、調整と結果の関係を理解することです。
4-1. 解析前トリミングの効果
ControlNetの効きは、解析前の画像の状態に大きく左右されます。
ここでは同じ元画像・Preprocessorで、トリミング有無だけを変えて比較します。
■実験条件
- 元画像:同一
- Preprocessor:同一(OpenPose Pose)
- ControlNet設定:固定
- 変更点:トリミングの有無
👉 解析前の画像整理が与える影響を見る実験です。
■元画像の比較


- 左:元画像そのまま
- 右:被写体をトリミングした画像
一見同じ情報でも、モデルが見る範囲は異なります。
トリミングにより、注目点が被写体に限定されます。
■解析画像の比較


- 情報の集中位置
- 背景の含まれ方
- 被写体構造の密度
トリミングなしでは、人物が画面内の一要素として扱われます。(※右腕が曲がっている解析画像になってしまっている。)
一方、トリミングありでは、同じポーズ情報でも人物の存在感が相対的に強まります。
■生成結果の比較


- 被写体の安定感
- 余計な要素の混入
- ポーズや形の再現性
設定は同じで、変えたのは画像の切り方だけです。
■まとめ
トリミングは「モデルに何を見せるか」を決める操作です。
ControlNet調整は、ノード設定より前から始まっています。
4-2. Canny閾値比較
Cannyは単純に見えて、線の強さ・密度で制御感が大きく変化します。
ここではPreprocessorは固定し、thresholdだけを変えて比較します。
■各パラメータの役割
- low_threshold
- どこから「線として拾い始めるか」
- 低いほど 細かいエッジまで拾う
- high_threshold
- 「これは確実に線だ」と判断する基準
- 低いほど 線が太く・多くなりやすい
- resolution
- 解析画像の解像度
■実験条件
- 元画像/モデル/Seed/プロンプト:固定
- プロンプト:high quality illustration, 1girl
- ネガティブプロンプト:(low quality:1.2), (bad anatomy:1.2)
- Preprocessor:固定(Canny Edge)
- ControlNet設定:固定
- 変更点:threshold(低/中/高)
- 低:low_threshold : 50、high_threshold : 100、resolution : 512(固定)
- 中:low_threshold : 100、high_threshold : 200、resolution : 512(固定)
- 高:low_threshold : 150、high_threshold : 255、resolution : 512(固定)
👉 線の量が与える影響を確認します。
・元画像

■解析画像の比較



- 左:細部・背景まで線だらけ(threshold:低)
- 中:主体中心でバランス良(threshold:中)
- 右:太い輪郭だけ残る(threshold:高)
同じ画像でも、解析情報量は大きく変わります。
■生成結果の比較



- 線が多い → 形は安定するが窮屈
- 中間 → 固定と自由のバランス
- 線が少ない → 自由度が高い
変えたのは、線の量だけです。
■観察ポイント
- 形の固定感はどこまで強まったか
- モデルの自由度はどこで失われたか
- 破綻や不自然さは、どの段階で出始めたか
■まとめ
Canny調整は「線を増減する」操作ではありません。
それは、モデルをどこまで縛るかを決める操作です。
4-3. Depth精度と自由度の関係
Depth系Preprocessorは、制御力が非常に強いのが特徴です。
安定する一方で、「効きすぎる」と感じやすいのもこの系統です。
ここでは、Depthの有無ではなく精度差に注目します。
■精度が高い=良い、ではない
Depthの精度差は、
- 固定の強さ
- 自由度の残り方
を大きく左右します。
制御の質が変わると捉えるのがポイントです。
■実験条件
- 元画像/モデル/Seed/プロンプト:固定
- プロンプト:high quality illustration, 1girl
- ネガティブプロンプト:(low quality:1.2), (bad anatomy:1.2)
- Preprocessor:Depth 系(Zoe Depth Anything/Depth Anything)
- ControlNet設定:固定
- 変更点:Depth の精度(高精度/粗め)
- 高精度:Zoe Depth Anything
- 粗め:Depth Anything
・元画像

■解析画像の比較


- 左:高精度:面構造・奥行きが細かい(Zoe Depth Anything)
- 右:粗め:大まかな奥行きのみ(Depth Anything)
同じDepthでも、情報量は別物です。
■生成結果の比較


- 左:高精度:配置が強く固定、安定する(Zoe Depth Anything)
- 右:粗め:大枠を保ちつつ変化しやすい(Depth Anything)
これは良し悪しではなく、制御の質が違うだけです。
■観察の軸
- 固定される ↔ 自由度が残る
- 安定する ↔ 表現の幅が広がる
精度を上げる=固定を強める
荒くする=自由度を残す
■まとめ
Depthは正確さを競うものではありません。
どこまで固定したいかを決めるための情報です。
4-4. 前処理の前処理
ここまで行ってきた調整は、
トリミング・線量調整・Depthの粗さ変更など、一見バラバラに見えます。
しかし本質はすべて同じです。
■共通点は「解析画像の作り方」
これまで触ってきたのは、
- 何を解析させるか
- どこまで解析させるか
- どれくらいの精度で解析させるか
生成を調整しているのではなく、解析の仕方を設計しているという点です。
■ControlNetの流れ
元画像 → 解析画像 → ControlNet → 生成結果
私たちが直接操作しているのは、常に 解析画像 です。
■主役はPreprocessorではない
よくある誤解は、
「Preprocessorを選べば終わり」という考え方です。
実際には、
- Preprocessorは入口
- 解析画像は 調整対象そのもの
ControlNetは、渡された解析画像の内容に反応します。
■4章まとめ
Preprocessor設定はゴールではありません。
解析画像は完成品ではなく素材です。
調整とは、モデルに「何を、どこまで伝えるか」を決める作業。
だからこそ、
Preprocessor調整は前処理の前処理 なのです。
5.複数ControlNetで固定を分担する
ControlNetは、増やせば強くなるものではありません。
重要なのは、何を固定し、何を任せるかの設計です。
ここからは、
複数のControlNetを足し算ではなく役割分担として使い、
固定したい部分を競合させずに同時制御する考え方を整理します。
5-1. 組合せ提案:Pose × Canny/Depth × Lineart
複数ControlNetの基本は、異なる種類の情報を別々に担当させることです。
同じ系統の情報を重ねると、ControlNet同士が競合します。
まずは、役割が明確に分かれる組み合わせを押さえます。
・元画像

人物:立ちポーズ
服装:短パン+Tシャツ
■構造と外形を分ける王道:Pose × Canny
この組み合わせは、
複数ControlNetを初めて使う場合でも成功しやすい代表例です。
Poseは骨格・関節、Cannyは輪郭を担当します。
中身(構造)と外側(形)が分離され、情報が重なりません。
・解析画像
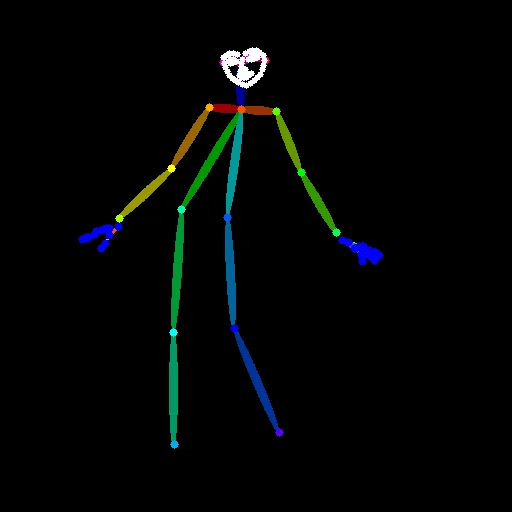

OpenPose
Canny
・生成結果

・プロンプト:high quality illustration, 1girl, soft knit sweater, mini skirt, autumn
・ネガティブプロンプト:(low quality:1.2), (bad anatomy:1.2)
ポーズは安定しつつ、服装や質感の自由度が残ります。
「姿勢は固定、絵作りは任せたい」場合に有効です。
※注意
[ControlNetを適用]のデフォルト強度(strength = 1.0)のまま適用すると、形状の指示が重なりすぎて破綻しやすくなります。
実用上は、以下のように強度を抑えるのがおすすめです。
・Pose:strength 0.3〜0.5(姿勢の安定を優先)
・Canny:strength 0.3〜0.4(輪郭は軽く補助する程度)
また、start_percent / end_percent を調整することで適用タイミングをずらし、
さらに安定させることも可能です。
※今回は特に設定変更せずに生成しています。
■空間と形を同時に安定:Depth × Lineart
Depthは奥行きや配置、Lineartは形状の輪郭を担当します。
構図全体が崩れにくく、背景と被写体の距離感が安定します。
・解析画像

Depth
Lineart
・生成結果

・プロンプト:high quality illustration, 1girl, geometric print clothing, beige hoodie,
velvet short pants, snow boots, Winter Background
・ネガティブプロンプト:(low quality:1.2), (bad anatomy:1.2)
建物・室内・複数オブジェクトを含むシーン向きです。
描き込みや表情はモデル側に任せられます。
■まとめ:成功する組み合わせの共通点
組み合わせの鍵は「数」ではなく、役割の切り分けです。
5-2. 効果が増えない組み合わせ(情報の衝突)
ControlNetを増やせば、制御が強くなるとは限りません。
特に、同じ系統の情報を重ねた場合、見た目上の破綻が起きなくても、制御効果がほとんど増えないことがあります。
■例①:Canny × Lineart
・解析画像の比較

ポイント:
- 解析画像の段階で、含まれる情報が非常に似ている
- 重ねても「新しい情報」が増えていない
・生成結果の傾向
輪郭の安定感はほぼ同じで、ControlNetを増やした明確なメリットは見られません。
■例②:Depth × Depth(精度違い)
・解析画像の比較


奥行き情報は両方とも「前後関係」を示しており、精度差があっても役割は同じです。
・生成結果の傾向
どちらか一方が実質的に優先され、両方を使った効果は限定的になります。
■まとめ
strengthを下げたり、start_percent / end_percent をずらすことで、
表面的な破綻は回避できます。
しかしその場合、複数ControlNetを使っている意味自体が薄れる
ことに注意が必要です。
5-3. 複数ControlNetの優先順位設計
複数ControlNetで最初に決めるべきなのは設定ではありません。
考えるべきは、何を一番崩したくないかです。
すべてを同じ強さで使うと、情報は衝突します。
ControlNetは同列ではなく、役割に序列をつけます。
■優先順位の考え方:崩れたら致命的なものを上に
例:人物イラストの場合
- 最優先:Pose
- 骨格・関節 → ここが崩れたら全てが破綻する
- 中優先:Depth
- 構図・奥行き → 世界観や安定感に影響
- 低優先:Canny / Lineart
- 形の目安 → 補助的なガイド
重要度が高いものほど、上位に置きます。
■優先順位=解析画像の「意味の重さ」
優先順位は、ControlNetの種類そのものではありません。
同じCannyでも、
主役か補助かで立ち位置は変わります。


- 左:主役Canny(輪郭が明確・情報量多め)
- 右:補助Canny(少しラフ・ガイド的)
解析画像を「答え」にするか「ヒント」にするかが設計です。
■strengthは設計の結果として決まる
優先度が高いControlNetほど、
「そのPreprocessorに適した強さ」で効かせます。
補助的なControlNetは、主役を邪魔しない範囲に留めます。
・strength配分イメージ
[ Pose ]
███████████████ 強
[ Depth ]
█████████ 中
[ Canny / Lineart ]
█████ 弱
これはテクニックではなく、設計の反映です。
「全部同じ数値」ではなく、「この役割だからこの強さ」
という理由がある状態が理想です。
■まとめ
ControlNetは、数で強くなるのではありません。
役割と優先順位で強さが決まります。
複数ControlNetは同列ではない
5-4. ControlNetとLoRAの役割分担
ポーズも構図も画風も、すべてControlNetで決めようとすると破綻します。
役割を背負わせすぎると、効きすぎ・不自然さの原因になります。
ControlNetは「表現」を作る道具ではない
■ControlNetとLoRAは得意分野が違う
- ControlNet:骨格・構図・位置関係
- LoRA:画風・可愛さ・雰囲気・質感
ControlNetは構造担当、LoRAは見た目担当です。
この境界を混ぜると、壊れやすくなります。
■LoRAを入れ込んだフロー
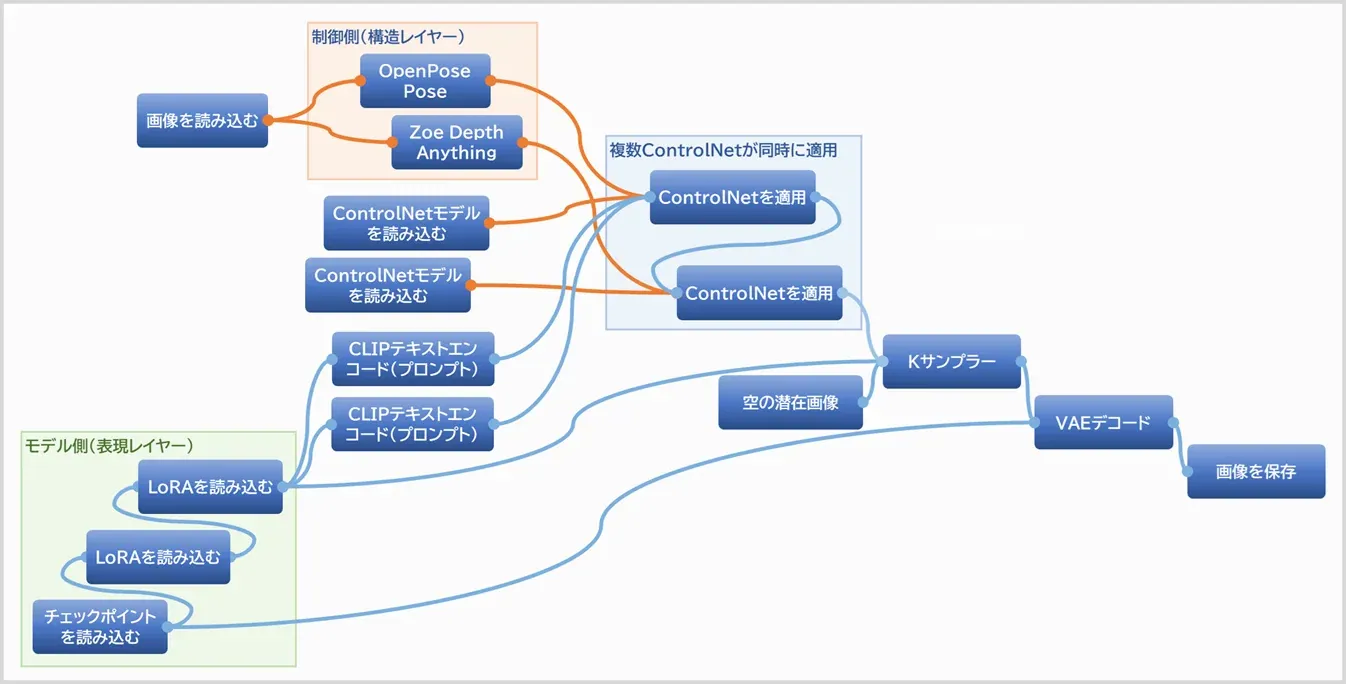
■役割分担したときの安定構成
- ControlNet:Pose/Depth
- LoRA:キャラクター/画風
一つ、シンプルな構成例を見てみます。
・元画像

- ControlNet
- Pose:ポーズ固定
- Depth:構図と奥行き安定
- LoRA
- キャラクターLoRA(目を綺麗に強調するLoRAを使用)
- 画風LoRA(水彩画風にするLoRAを使用)
・解析画像
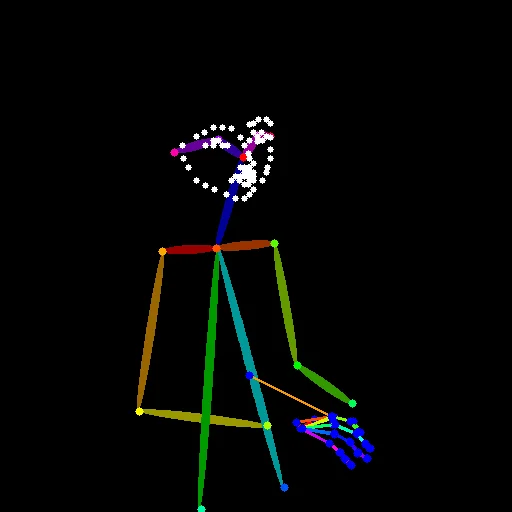

OpenPose
Depth
・生成結果

ControlNetが「崩れない土台」を作り、LoRAが「見た目の方向性」を決めます。
競合せず、自然に噛み合う構成です。
■ControlNetは骨組み、LoRAは味付け
ControlNetは構造、LoRAは表現
上下関係ではなく、役割の違いです。
骨格はControlNetに、可愛さはLoRAに任せましょう。
■5章まとめ
ControlNetは、設定ではなく設計の道具です。
6.思い通りにならないときの対処リスト
理解して設計しても、生成が崩れることはあります。
この章は、詰まったときに戻るためのチェックリストです。
上から読む必要はなく、症状から原因を引きます。
設定の正解は示しません。
■トラブル全体マップ
- 形が崩れる
- 姿勢・構造情報は渡しているか
- NO:情報不足の可能性 → 6-1へ
- YES:他の情報と競合 → 6-4へ
- 姿勢・構造情報は渡しているか
- 別人になる
- プロンプト/LoRAが強すぎないか
- YES:情報過多 → 6-2へ
- プロンプト/LoRAが強すぎないか
- 背景が変わる
- 奥行き or 輪郭で背景を固定しているか
- NO:情報不足 → 6-3へ
- 奥行き or 輪郭で背景を固定しているか
- 精度を上げると壊れる
- ControlNetを重ねすぎていないか
- YES:情報衝突 → 6-4へ
- ControlNetを重ねすぎていないか
ControlNetのトラブルは、ほとんどが
情報が足りない/強すぎる/競合している
のどれかです。
6-1. 形が崩れる
■症状
まずは、「形が崩れる」とはどういう状態かをはっきりさせます。
一見「ControlNetが効いていない」と感じやすい状態です。
■よくある誤解
「strengthを上げれば固定される」と考えがちですが、多くの場合は解決しません。
原因は制御の強さではなく、渡している情報の種類にあります。
■原因の切り分け
- 姿勢(構造)情報を渡していない
- 情報が弱い/曖昧
- 背景など余計な要素を解析している
たとえば、
- Canny・Lineartのみ → 外形は取れるが骨格は指定されない
- 被写体が小さく背景が広い → 何を守るべきか判断できない
この状態では、
ポーズや手足の位置が毎回ブレるのは自然な結果です。
■対処の方向性
「強くする」ではなく「足す・整理する」 方向で考えます。
- 姿勢系Preprocessorを追加
- OpenPose / DWPose
→ ポーズ・関節・向きを明示的に渡す
- OpenPose / DWPose
- トリミングで解析対象を明確化
- 被写体を大きく切り出し、背景解析を減らす
重要なのは数値ではなく、モデルに“形の答え”を渡せているか という視点です。
■まとめ
6-2. 別人になる
■症状
まず、このトラブルの典型例を整理します。
この状態になると、
ControlNet、全然効いてないのでは?
■原因候補の整理
多くの場合、原因はControlNetではなく他の情報が強すぎること。
重要なのは「情報量」ではなく どの情報が最も強いか です。
■ControlNet側の問題ではない例
同一ControlNet・Seedで「LoRAあり/なし」だけを切り替えると、
- ポーズや構図は同じ
- 顔立ち・雰囲気だけが変わる
つまり、 ControlNetは効いているが、後から上書きされている 状態です。
■対処の方向性
やるべきは「強化」ではなく 役割の整理。
- LoRAの影響を弱める(キャラを決めすぎない)
- Style LoRAは画風寄りに使う
- ControlNetを「形担当」に戻す(骨格・向き・比率)
目的は「誰かっぽくする」ではなく この形を保ったまま描かせる こと。
■まとめ
6-3. 背景が変わる
■症状
このトラブルは、かなり頻出です。
特に、「キャラは良いのに背景が落ち着かない」ケースで頻発します。
■原因の構造
背景は、何も指定しなければ自由に描かれる
Poseや形だけ固定しても背景には制約がなく、モデルが毎回「それっぽい背景」を補完するため、
キャラは同じでも背景だけが暴れます。
■対応する情報の提示:Depth/Canny
背景を安定させるには 背景の情報を明示的に渡す
- Depth:奥行き・配置・距離感を固定
- 手前/奥、壁や建物の位置など
「どこに何があるか」を構造として固定 したいときに有効です。
- Canny:背景の輪郭・シルエットを固定
- 建物の形、窓や柱、地形の境界など
「背景の形だけは守りたい」という場合に向いています。
■注意点:固定しすぎの副作用
Depth/Cannyは背景を安定させる一方で、
結果として「全部固定したのに破綻する」状況を招くことがあります。
■まとめ
6-4. 精度を上げると壊れる
■症状
これは、多くの人がハマるトラブルです。
多くの人が「設定値が悪い?」と考えますが、原因は別にあります。
■典型パターン
破綻しやすい組み合わせの例:
共通点は 同じ種類の情報を別ルートから重複して渡している こと。
■解析画像の重なり
並べて見ると、
- 似た線
- 似た奥行き
- 似た構造
が複数存在し、モデルは「どちらを守るべきか」判断できません。
結果として線が歪み、面が破綻し、形がねじれます。
■まとめ
ControlNetは「多いほど強い」「精密ほど正しい」仕組みではありません。
壊れたのは努力不足ではなく、同じ情報を渡しすぎたためです。
『減らす/役割を分ける』を意識するとよいです。
6-5. 迷ったときの判断順
ControlNet調整で一番やってはいけないのは、
ことです。
迷ったときは、必ずこの順番で切り分けます。
■判断フローチャート
1️⃣ 形は崩れているか?
- ポーズが安定しない
- 手足や向きが毎回変わる
- Yes:姿勢情報・解析不足を疑う
- 解決方法:Pose / トリミング
- No:次へ
- Yes:姿勢情報・解析不足を疑う
2️⃣ 別人になっているか?
- 顔つきが変わる
- キャラ性が上書きされる
- Yes:LoRA・プロンプトの影響過多
- ControlNetの問題ではない
- No:次へ
- Yes:LoRA・プロンプトの影響過多
3️⃣ 背景が変わるか?
- 構図が安定しない
- 被写体は合っている
- Yes:Depth / Canny を検討
- 背景情報を渡す
- No:次へ
- Yes:Depth / Canny を検討
4️⃣ 精度を上げたら破綻するか?
- ControlNetを増やした
- 解析を細かくした
- Yes:情報過多・衝突を疑う
- 重複していないか確認
- Yes:情報過多・衝突を疑う
このフローで大事なのは、
- 数値を触る前に
- ControlNetを足す前に
まず、
「どの種類の問題か」を決めること
です。
■6章まとめ
うまくいかないときは「センスがない」と思う前に、この章へ戻ってください。
7.次のステップ:ControlNetで画像を進化させる
■視点を「生成」から「編集」へ
これまでは「思い通りに生成する」ためのControlNetを扱ってきました。
ここからは 既存の画像をどう変えるか に焦点を移します。
ControlNetは安定生成の道具であり、同時に 画像を編集・発展させるためのツール でもあります。
この章は設定調整ではなく、制作フェーズへの入口 です。
7-1. ControlNetは「選んで調整する」段階へ
ControlNetとの向き合い方は、ここまでで大きく変わったはずです。
・Before
・After
■ControlNet理解のステップ
- 使ってみる
- 効き方を観察する
- 調整する
- 組み合わせる
- 選んで設計する(👈今ここ)
ControlNetは「強くする技術」ではなく、「使い分ける技術」
ここまで来たあなたは、
もう設定に振り回される側ではなく、ControlNetを“選ぶ側”に立っています。
7-2. Inpaint × ControlNetという考え方
完成画像はゴールではなく、次の制作のスタートです。
■Inpaint × ControlNet の考え方

- 元画像を用意
- 修正したい部分だけマスク
- ControlNetで「崩したくない構造」を渡す
- 差分だけ生成する
- 進化!
発想は「全部描き直す」ではなく、必要部分だけ進化させること。
■ワークフロー例
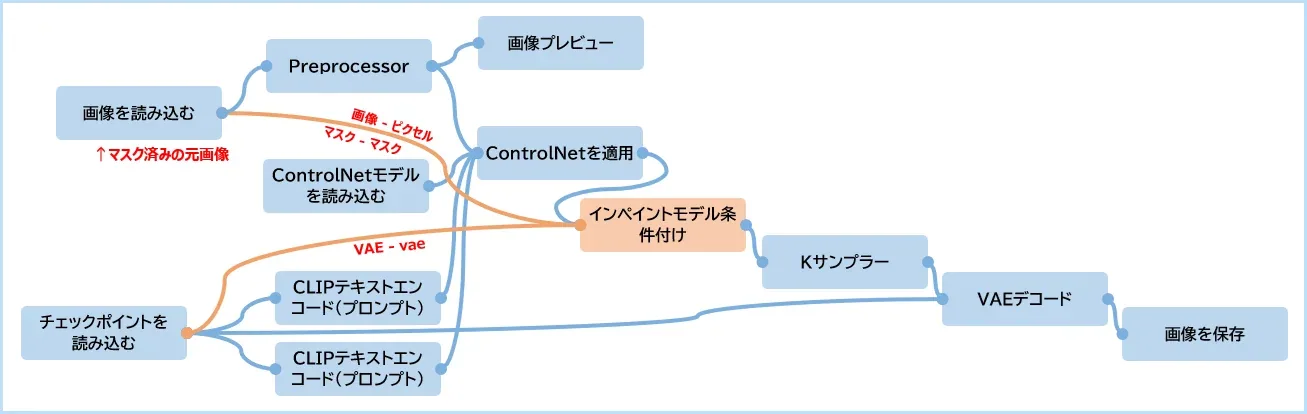
■実例イメージ



元画像
マスク処理済み画像
生成画像
- ポーズは維持
- 服装及び背景を変更
- プロンプト:high quality illustration, 1girl, white long skirt, Building in the background
ControlNetは、生成にも編集にも使える道具です。
7-3. 生成から編集のフェーズへ
ここから先は、プロンプト調整ではなくどこを変え、どこを残すかという編集判断のフェーズです。
■差分生成という考え方
- 固定するもの
Pose / 構図 / 奥行き - 変えていくもの
表情 / 衣装 / 背景 / 雰囲気
すべて動かさず、すべて固定せず、差分だけ設計する —— これが次のフェーズです。
■次に学ぶとよいテーマ
あなたはもう「当たるまで回す」段階ではなく、意図して画像を育てる段階にいます。
■このページのまとめ
ControlNetは、
重要なのは、変えたい部分だけ選ぶこと。
構造を理解し、情報を選び、必要な差分だけ与える。
今は、設計して画像を作るフェーズに突入しています!
—— ControlNetは、
テクニックではなく、制作思考のための道具なのです。
コメント