このポーズのまま、別の服装にしたいんだけどなぁ
そんなとき、ControlNetが 形のコントロール を助けてくれます。
この記事では、とりあえず迷わず始められるように必要なしくみ・前処理・モデルの選び方をまとめました。
1.ControlNetの基礎:画像を「制御」する仕組み
Stable Diffusion はプロンプトから画像を生成できますが、「構図を固定したい」「ポーズを再現したい」「線画を清書したい」といった“形や構造の制御”は苦手です。
そこで登場したのが ControlNet です。
ControlNetを使うことで、元画像から抽出した“形の情報(解析画像)”を生成過程に注入し、出力画像を制御できるようになります。
この章では、ControlNetの基本的な考え方を4つの切り口から整理します。
1.1 ControlNetとは何か:通常の生成との違い
通常のStable Diffusionは、
プロンプト(言語)→ 潜在空間(ノイズ)→ 画像
という流れで画像を生成します。
この仕組みは自由度が高い反面、ポーズや構図、輪郭といった“形”の指定は苦手です。
ControlNetはこの弱点を補う拡張です。
・入力画像から「構造(エッジ・姿勢・深度など)」を抽出
・抽出した情報を、生成モデルに追加で渡す
・生成画像の形や配置をコントロール
つまりControlNetは、
「プロンプトだけでは曖昧になりがちな“形”の部分を、画像から補強する仕組み」
と言えます。
結果として――
・通常生成:自由だが、形が安定しにくい
・ControlNet生成:形が安定し、破綻が少なく、再現性が高い
という違いが出ます。
1.2 解析画像が果たす役割:なぜ前処理が必要なのか
ControlNetは、入力画像をそのまま使うのではなく、生成のガイドとなる「形の情報(特徴量)」を利用します。
元画像は情報量が多すぎるため、前処理で輪郭・骨格・深度といった核心部分だけを抽出する必要があります。
| 元画像 | 解析画像 | 抽出される核心情報 |
|---|---|---|
| 物体や人物が写った写真 | Canny | 輪郭情報 |
| 人物が写った写真 | OpenPose | 人体の骨格・姿勢 |
| 構造があるシーン写真 | Depth Map | 奥行き・距離 |
このように情報を絞り込むことで、生成結果に元画像の形を正確に反映できる ようになります。
解析画像= 「形の核心部分だけを抽出して減量した状態」
1.3 情報の流れ:どこで制御され、どこに影響が出るのか
ControlNetは、Stable Diffusion の中核である UNet に追加の制御信号を注入する仕組み です。
■生成の流れ(簡略図)
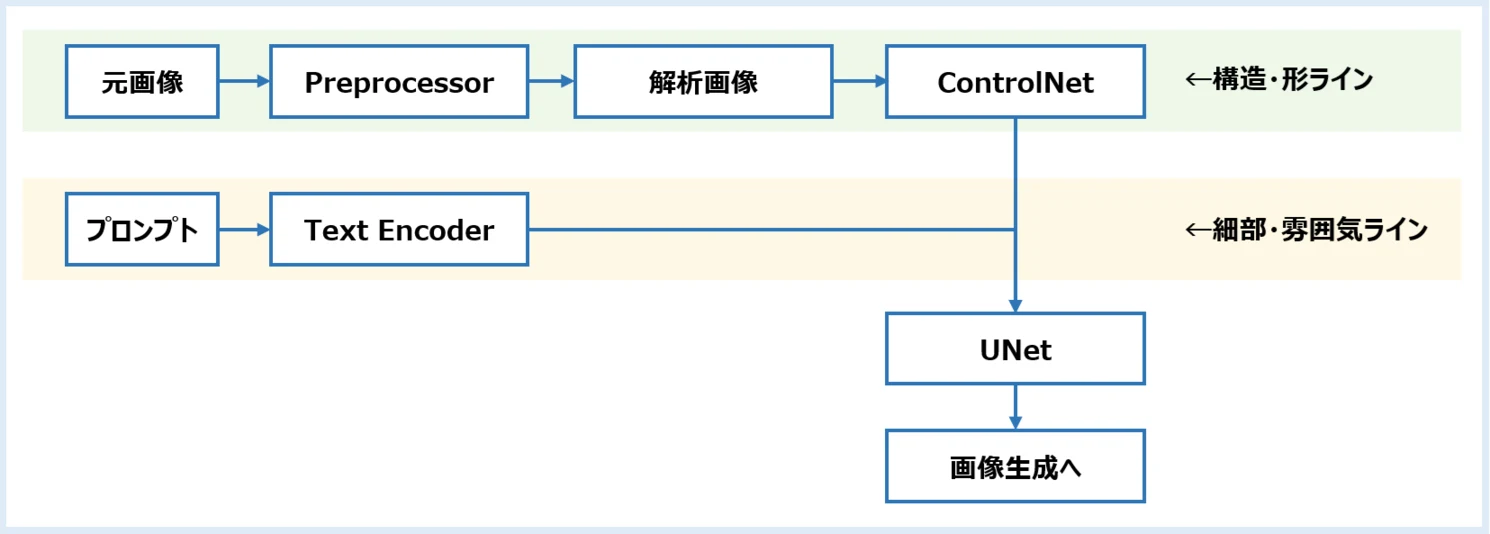
特に UNet の中間層(構図や形に強く影響する部分) に情報を与えるため、プロンプトよりも“形”が優先されやすくなります。
その結果、役割は次のように分かれます。
・ControlNet:構造・形を担当
・プロンプト:細部・雰囲気を担当
また、重みや開始・終了ステップを調整することで、制御の強さも変更できます。
1.4 ControlNetは ”万能ではない”
ControlNetは強力ですが、限界もあります。押さえておくべき点は次のとおりです。
- 解析画像が誤っていれば出力も崩れる
(例:ポーズ抽出が破綻していると形も破綻) - 形は制御できても、画風・質感は別領域
→ LoRAやモデル選択との併用が必要 - 制御が強すぎると創造性が失われる
→ weightを上げすぎると“トレース寄り”になる - 粗い解析画像では細部を反映できない
→ Cannyは輪郭のみ、Depthは奥行きのみ - モデルの限界を超える再現は不可能
→ ControlNetは方向付けであり、万能変換ではない
つまり ControlNet は「方向付けのための補助輪」であり、
生成モデル・プロンプトと並ぶ一つの要素にすぎない という理解が重要です。
2.ControlNetを使うための下準備:ノードの導入
ControlNetを使うには、まず ControlNet用のカスタムノードを導入できる環境 を整える必要があります。
ComfyUIを入れた直後には、これらの追加ノードが含まれていないため、自分で導入する作業が必要です。この章では、ControlNetを利用可能にするための 最初のセットアップ(ノード導入) を解説します。
※この段階ではモデルの準備は不要です。 モデルについては 5章で扱います。
2.1 ControlNetを使うには何が必要?:ノード導入の役割
ControlNetは、元画像から輪郭・姿勢などの特徴を抽出し、その情報を使って生成を制御します。
この“解析”を行うために、ControlNet専用のノードが必要です。
利用可能になる主なノード:
・ControlNetLoader / ControlNetApply
・各種 Preprocessor(Canny、OpenPose など)
・Preprocessor関連の補助ノード
これらが入っていないと、ControlNet用ノード自体が表示されません。
そのため、まず ControlNet関連ノード(comfyui_controlnet_aux)を追加する 必要があります。
🔰 まずは「必要なノードを入れるだけ」と理解しておけば十分です。処理内容は後の章で自然に理解できます。
2.2 導入方法①:手動で comfyui_controlnet_aux を追加する
最も確実な導入方法は、リポジトリから直接ノード一式をダウンロードする方法です。
修復やアップデートもしやすく、環境の仕組みを理解するのにも向いています。
■手順
1.comfyui_controlnet_aux のGitHubページへアクセス
2.ZIPをダウンロードし、解凍

3.解凍してできたフォルダを ComfyUIの 「custom_nodes」 フォルダへ配置
📌 パス例(Windows)
ComfyUI_windows_portable\ComfyUI\custom_nodes
└ comfyui_controlnet_aux ←解凍したフォルダ
4.ComfyUIを再起動
再起動後、ノード一覧に ControlNet系ノード が追加されていれば成功です。→ 2.4へ
2.3 導入方法②:ComfyUI Manager からインストールする
もし ComfyUI Manager(GUIの追加管理ツール) を導入している場合は、クリック操作だけでインストールできます。環境構築を急ぎたい方・アップデートを容易にしたい方に向いています。
■手順
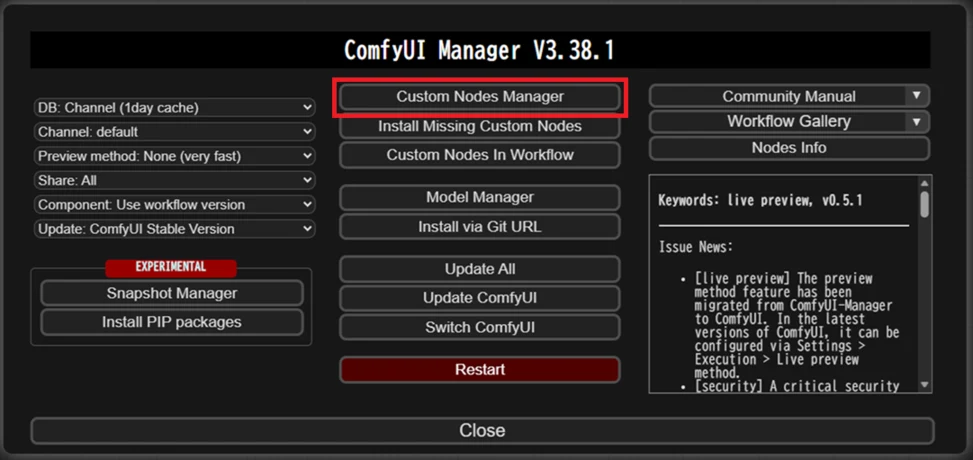
1.ComfyUI Manager を開く
2.Custom Nodes Managerをクリック
3.「comfyui_controlnet_aux」 を検索 / Install ボタンを押す
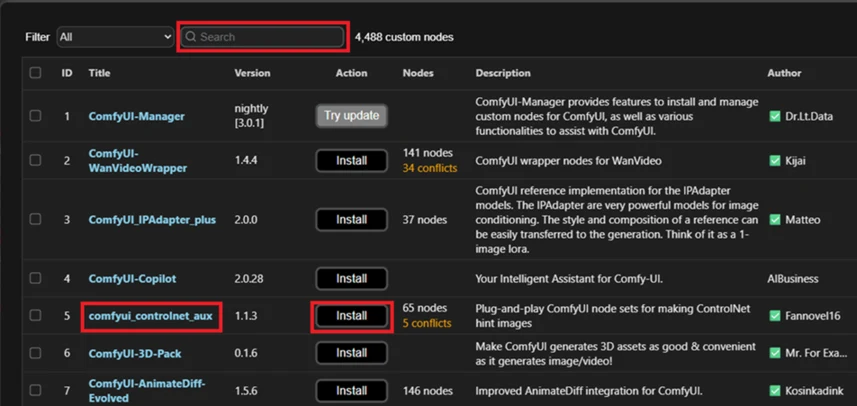
※記事作成時は、comfyui_controlnet_auxが5つ目に見えてるので検索するまでもありませんでした。
4.ComfyUIを再起動
ComfyUI Manager環境が整っている場合はこちらが簡単です。
一方、ComfyUI Managerを使っていない場合は 前項の2.3 の手順での手動導入となります。
2.4 ControlNetノードが導入されたか確認する:チェックのポイント
導入が完了したら、ControlNet関連ノードが表示されるか確認しましょう。
1.ノード検索欄で 「control」「apply」「openpose」 などと入力
2.以下のようなノードが表示されればOK
・ControlNetLoader
・ControlNetApply
・Canny Edge
もし見当たらない場合:
・custom_nodes 配置パスのミス
・ZIP解凍フォルダが二重階層になっている
・ComfyUIを再起動していない
・Managerの反映がまだ
といった点を確認してみてください。
👍 この確認ができれば、次章でいよいよ接続を開始できます!
3.まずは接続してみよう:最小構成のノード接続
ControlNetを理解する最初のステップは、「どのノードを置き、どうつなぐか」 を把握することです。この章では、最小限のノード構成を作り、“ControlNetを使った生成の型” を作ります。
3.1 最小構成の全体像:どんなノードが必要?
ControlNetを使うために必要な要素は、次の4つです:
| 要素 | 内容(要約) | 対応するノード |
|---|---|---|
| 画像を入力する | ControlNetに解析させる元画像を読み込む | Load Image |
| 画像を解析する | ControlNet用に画像から形・線・構造などを抽出する | Canny / Depth / OpenPose などの Preprocessor |
| 解析情報を生成に反映する | 解析画像をもとに生成モデルへ制御情報を渡す | ControlNet Loader(モデル読み込み)→ ControlNet Apply(適用) |
| テキストから画像を生成する(通常生成) | 通常の Stable Diffusion による生成処理 | Checkpoint Loader, CLIP Text Encode, KSampler, UNet |
以下は、4つの要素をつないだ最小構成のノード例です。
まずは“ControlNet付きの画像生成”の全体像をつかみましょう。
■最小構成のワークフロー
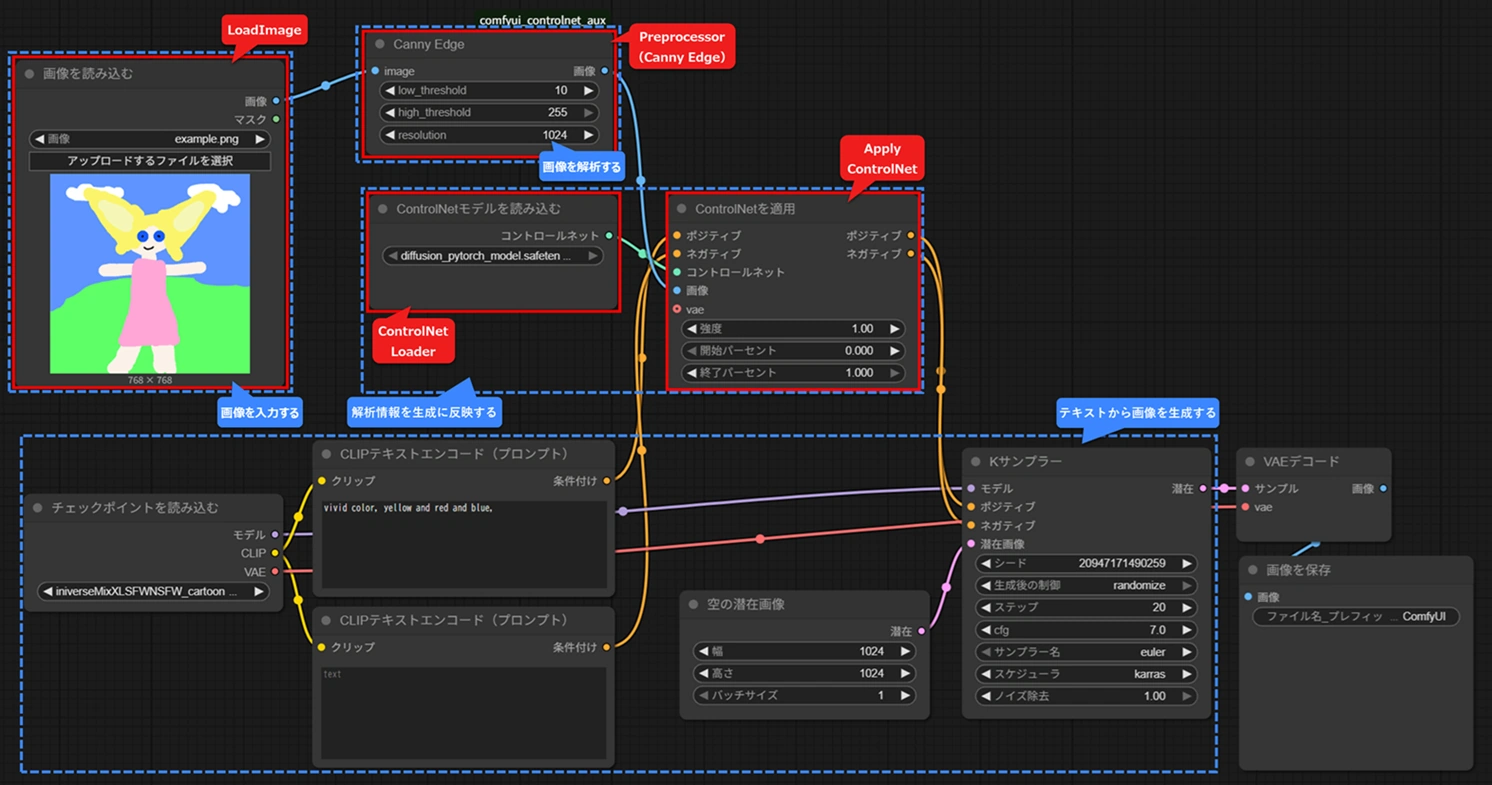
※赤枠は今回追加したノード、青枠は必要な要素です。
Preprocessorの出力(解析画像)が Apply ControlNet を通じて UNet に渡され、生成が制御される 仕組みになります。
3.2 使うノードと役割(初心者向けまとめ)
ここでは、最小構成に含める代表的なノードを解説します。
| ノード | 役割 | 初心者の理解ポイント |
|---|---|---|
| Load Image | 解析元となる画像を読み込む | PNG/JPG なら大体OK。※マスク端子は今は使いません |
| Preprocessor(Canny / DWpose / Depth など) | 「線だけ」「ポーズ」「奥行」などを抽出 | 解析画像 = ControlNetの命 |
| ControlNet Loader | ControlNetモデルを読み込む | モデルの種類は 5章で解説 |
| Apply ControlNet | 解析情報をUNetに渡す | これが“制御中継点” と理解すればOK |
| Checkpoint Loader | 生成モデル本体を読み込む | – |
| CLIP Text Encoding (Prompt) | プロンプトを読み込み変換 | – |
| Empty Latent Image | サンプルに必要な「入力ノイズ」生成 | サイズ=最終画像サイズ |
| KSampler | 画像生成プロセス(拡散計算) | ControlNetの影響を受ける場所 |
| VAE Decode | latent → 画像に戻す | 最後に必須 |
| Save Image | 画像保存 | – |
3.3 画像を読み込む:Load Image ノード
ControlNet を使うには、まず「形の手がかり」となる参照画像を用意します。
その役割を担うのが Load Imageノード です。ここでは「どの画像を解析の出発点にするか」を指定します。
このノードで画像を読み込むと、後続の Preprocessor ノードで輪郭抽出や深度推定などの解析が可能になります。
解析結果は最終的に Apply ControlNet ノードを通じて画像生成に反映されます。
■Load Image ノードの役割
・解析の起点となる画像を選ぶ
※PNG / JPG など一般的な形式でOK
・Preprocessor に渡す準備をする
■画像選びのポイント
・形が明確な画像ほど解析が安定(例:ポーズ、輪郭、形状)
・色や質感は重視しなくてよい、構造重視
・「生成したい構図」に近い画像を選ぶと効果が分かりやすい
これで ControlNet に渡す元画像が準備できました。次は Preprocessor による形の抽出処理に進みます。
3.4 画像から形を抽出する:Preprocessor ノード
ワークフローにおいて、元画像とControlNetをつなぐ架け橋となるのが Preprocessor ノードです。Preprocessor は、読み込んだ画像を ControlNet が理解しやすい特徴画像に変換します。
■代表的な Preprocessor の例と用途
| Preprocessor | 抽出する情報 | 使う場面 |
|---|---|---|
| Canny | 輪郭(エッジ) | 元画像の形をそのまま反映したい |
| OpenPose | 人物の骨格・ポーズ | ポーズを維持しつつ見た目を変えたい |
| Depth Map | 奥行き・距離情報 | 背景の立体感を残したい |
| M-LSD Lines | 建物の直線構造 | 建築物の形だけ活かしたい |
■出力される画像は “形の情報” が中心
Preprocessor の結果は、色や質感を捨てて 形だけを強調した特徴画像になります。
例:Canny → 白地に黒線の線画のような画像。
これは、次の章の Apply ControlNet で形を反映させるための「材料」と考えると理解しやすいでしょう。
■まとめ
・Preprocessor ノードは 画像解析の担当 である
・出力は ControlNet に渡すための形データである
・Preprocessor によって 抽出される特徴が変わる
3.5 解析画像で形を指定する:Apply ControlNet ノード
Apply ControlNet ノードは、Preprocessor が作った「形を表す解析画像」を生成モデルに反映させるためのノードです。端的に言えば 「この形を守りながら画像を作ってね」 と指示する役割を担います。
■Apply ControlNet の入力と出力
・解析画像:Preprocessor が抽出した輪郭・骨格など(入力元:Preprocessor)
・ControlNetモデル:形を反映する専用モデル(入力元:ControlNet Loader)
・出力端子:生成パイプラインへ渡す出口(KSampler ノードへ)
■大事なポイント
Apply ControlNet は「形を抽出」しません。
すでに Preprocessor で作った解析画像を “どの強さで”“どこまで反映させるか” を決めるノードです。
■ControlNet の強さを調整
Apply ControlNet ノードでは、解析画像を生成に反映する強さと適用タイミングを細かく設定できます。これにより「序盤は形を厳密に守り、後半で自由にディテールを付ける」といったような柔軟な制御も可能になります。
| パラメータ | 意味 | 効果 |
|---|---|---|
| strength | 解析画像の影響度 | 値が大きいほど元画像の形を維持 |
| start_percent | 反映開始のタイミング | 0.0 が開始時、値が大きいほど後半から適用 |
| end_percent | 反映終了のタイミング | 1.0 で生成完了まで反映、短くすると後半は自由生成 |
■ポイント
・strength は「どれだけ形を守るか」
・start_percent / end_percent は「その拘束をいつ適用するか」
■初心者向けのおすすめ設定
| 用途 | 設定例 |
|---|---|
| 元画像の形をしっかり保持したい | strength 0.9~1.2 / start 0.0 / end 1.0 |
| 形は使うが、後半は自由に細部作り込みさせたい | strength 0.8 / start 0.0 / end 0.7 |
| ざっくり形だけ借りたい | strength 0.5~0.7 / start 0.0 / end 0.5 |
💡Tips
形が強すぎると感じたら strength を下げるより、end_percent を短くするほうが自然に形の雰囲気を残しつつ、プロンプトの内容を反映させやすくなります。
“strength” で形の強さを決め、“start/end” でその拘束を適用する区間を決める。
これが Apply ControlNet の調整の本質。
ControlNetを適用するための接続はこれで完成です。
次は、どの「形」を抽出するか——Preprocessorの選び方に進みましょう。
4.Preprocessorとは:役割と代表的な種類
Preprocessor(プリプロセッサ)は、元画像から形・線・構造・深度などの骨格情報を抽出し、その結果を ControlNet に渡す中間処理です。
■役割
・元画像を解析して ControlNet が扱いやすい特徴画像 を作る
・ControlNet が行う「生成時の方向づけ」のための 設計図を取り出す作業 に相当する
・抽出する設計図の種類を変えると、生成結果が大きく変わる
■この章の目的
・Preprocessor が 何をしているかを整理する
・主な種類と違い、使い分けの考え方を段階的に示す
・「目的に応じて適切な Preprocessor を選べる」状態を目指す
Preprocessor は 画像生成のための設計図を作る解析ノード であり、選択次第で生成の方向性が変わります。
4.1 Preprocessorは何をしている?:役割と考え方の整理
Preprocessor は元画像の特徴を ControlNet が使える形に変換するフィルタです。単なる読み込みではなく、生成に必要な「設計図」を抽出して要約します。
■処理の流れ
元画像 → Preprocessor → 構造データ → ControlNet → 生成ガイド
■なぜ“種類の違い”が大事なのか
・抽出する情報がそのまま生成結果に反映されるため、何を残し何を捨てるかの選択が結果を大きく左右します。
・例えば、Canny は構図を維持しやすいが細部は変わりやすく、OpenPose はポーズは再現するが服のディテールは継承しない といった傾向があります。
Preprocessor は「目的に合った形の情報だけを取り出す」解析ノードであり、適切な選択が生成の再現性と意図のコントロールに直結します。
4.2 Preprocessor主要タイプ総覧:用途と特徴まとめ
Preprocessor の種類で、ControlNet が「どの形を残すか」「どれだけ元画像に寄せるか」が決まります。ここでは制作でよく使う5つの代表タイプに絞り、それぞれで 何を制御できるか/どんな用途向きか を把握することを目的とします。
まずは全体像をざっくり掴み、細かいパラメータは後回しで構いません。これにより「どの Preprocessor を選べば意図した形が得られるか」を判断できるようになります。
■Preprocessorの主要5タイプと代表ノード
どれを選べばいい? が最速で判断できるよう、種類ごとに一覧化しています。
※種類は大分類、ノードはその一例です。全てを覚える必要はありません
① 輪郭/線/形 ―― 形の輪郭そのまま維持したいとき
| ノード名 | 長所 | 主な用途 |
|---|---|---|
| Canny Edge | 情報量のバランスが良く扱いやすい | 人物も背景も万能、まずはここから |
| HED Soft-Edge Lines | 抽象度が高く線が細い | 雰囲気保持、写実→イラスト化との相性〇 |
| M-LSD Lines | 直線の抽出に強い | 建築・背景の形状維持、パース崩壊防止 |
| Scribble Lines | 抽象度が高い、線が少ない | スタイル変換、構図テンプレート |
② 人体・ポーズ ―― ポーズ・手足・骨格を再現したいとき
| ノード名 | 長所 | 主な用途 |
|---|---|---|
| OpenPose Pose | 定番、扱いやすくバランス良い | 全身ポーズの制御、構図の再現 |
| DWPose Estimator | 高精度、手の形も安定 | 指・顔の表現を維持したまま再生成 |
③ 奥行き・立体 ―― カメラ構図や距離感を保ちたいとき
| ノード名 | 長所 | 主な用途 |
|---|---|---|
| Depth Anything | 現行で最もバランスが良い深度 | 屋内〜屋外まで万能、背景の奥行き再現 |
| Zoe Depth Anything | 距離表現が強い、人物に強い | ロケ写真からの再生成、自然光の残存 |
| MiDaS Depth Map | 古参で安定・互換性高い | カメラ構図維持、写真の立体感保持 |
| LeReS Depth Map | 高精度・細部に強い・安定 | 3D再構築、AR |
④ 領域分割・構造 ―― 背景の設計図を残したいとき
| ノード名 | 長所 | 主な用途 |
|---|---|---|
| SAM Segmentor | 要素ごとに分割可能 | 人物だけ残す、背景を差し替える |
| M-LSD Lines | 直線構造に強い | 建築物の形状・背景のパースを維持 |
⑤ 線画化(アニメ/イラスト)―― 写真を線画ベースに再生成したいとき
| ノード名 | 長所 | 主な用途 |
|---|---|---|
| Anime Lineart | アニメ絵に馴染む線 | 元絵を“アニメ作画風”に変換 |
| Standard Lineart | 線が強くパキッとする | 漫画的・劇画的な線表現に |
| Realistic Lineart | 写真を線画化 | 写真から似顔絵を作りたい時に最適 |
■選び方の大まかな目安
・元画像の構図や形をほぼ維持したい → ①輪郭/線/形、 ③奥行き・立体
・ポーズや人物の再現が最優先 → ②人体・ポーズ
・背景を変えたい/要素を分けたい → ④領域分割・構造
・アニメ化/線画化したい → ⑤線画化
次のセクションでは、この5種類から“目的別に最適解を選ぶ”チャートを用意しました。
「元画像をどこまで残したいか」「何を変えたいか」を軸に、迷わず選べるようになります。
4.3 どれを選べばいい?:目的の Preprocessor選び
Preprocessor はまず 「元画像のどの情報を再利用したいか」 で選びます。輪郭・ポーズ・奥行きなど目的を決めると候補が自然に絞れます。下の流れで当たりをつけ、実際に数種類を試して違いを確認してください。
まずは目的から逆算して候補を選び、試行で最適な Preprocessor を見つけるのが早道です。
■ 質問形式の選び方ガイド(目的 → 種類 → 代表ノード)
Q1.元画像の “何” を活かしたい?
| 活かしたい情報 | 推奨の種類 | 代表ノード |
|---|---|---|
| 形・輪郭・構図をほぼそのまま使いたい | 輪郭/線/形 | Canny / HED / M-LSD |
| 姿勢・動き・ポーズだけ使いたい | 人体・ポーズ | OpenPose / DWPose |
| 奥行き・立体感を反映したい | 奥行き・立体 | Zoe Depth / LeReS Depth Map |
| 服・髪・肌・背景を領域ごとに扱いたい | 領域分割・構造 | SAM / M-LSD |
| 線画風の “骨格” を元にしたい(イラスト寄り) | 線画化 | Lineart |
Q2.どれくらい “元画像に合わせたい”?
| 近さのニュアンス | 推奨の種類 | 代表ノード |
|---|---|---|
| ほぼ同じにしたい(忠実) | 輪郭/線/形 | Canny / HED / M-LSD |
| ポーズだけ借りたい(中間) | 人体・ポーズ | OpenPose / DWPose |
| 奥行きは残したい(やや抽象) | 奥行き・立体 | Zoe Depth / MiDaS |
| 要素の “カテゴリ” を維持したい(抽象) | 領域分割・構造 | SAM Segmentor |
| 線の雰囲気だけ残したい(自由寄り) | 線画化 | Lineart |
Q3.生成したい画像は?(用途 × 向いている種類)
| 作りたい画像の方向性 | 推奨の種類 | 代表ノード |
|---|---|---|
| 写真の構図そのままで衣装差し替え | 輪郭/線/形 | Canny / HED / M-LSD |
| ポージングが映えるキャライラスト | 人体・ポーズ | OpenPose / DWPose |
| 背景+人物の奥行き感を再現 | 奥行き・立体 | Zoe Depth / MiDaS |
| キャラクター + 背景を塗り分けて整えたい | 領域分割・構造 | SAM Segmentor |
| アニメ風・コミック調に寄せたい | 線画化 | Lineart |
ここまでで、目的に合う Preprocessor の目星は付いたはずです。
ただし、 「何でも任せられる1つ」 は存在しません。大切なのは、用途に合う“形”を見極めること。
次の節で、その考え方をまとめます。
4.4 万能はない:用途に合う“かたち”を選ぶコツ
Preprocessor は万能ではなく「特徴抽出の型」です。選ぶプリプロセッサによって、元画像のどの要素が残るかが大きく変わります。
■最初に “何を残したいか” を決める
Preprocessor は 「元画像のどの形を残すか」 を決める道具です。迷ったときは、最初に “残したいもの” をひとつに絞りましょう。
“何を残したいか”を最初に決め、その形が一番はっきり見える Preprocessor を選ぶ。
例:
・動き・ポーズを残したい → OpenPose / DW Pose
・厚み・雰囲気を残したい → Depth系(Zoe / MiDaSなど)
・輪郭・線を残したい → Canny / Lineart
先に残したいものを決めてしまうと、「どれにしよう?」という迷いが一気に減ります。
■ まとめ
・万能な Preprocessor はない
・まず“残したい形”を決める
・その形が一番はっきり見える Preprocessor を選ぶ
5.ControlNetモデルの種類と選び方
ControlNetモデルは「画像の形・構造」を左右する核心部です。ControlNetモデルは多種多様です。世代や種類に惑わされないよう、本章では「目的」から逆引きして、自分に最適なモデルを迷わず選べる基準を提示します。
5.1 ControlNetモデルとは:役割と「形を制御する考え方」
Preprocessor が「画像から形の情報を抽出する装置」だとすれば、ControlNetモデルは「形を制御する翻訳者」です。生成プロセスにどれだけ・どのように反映するか を決めます。
通常の生成はテキストやノイズから形も細部も同時に作るため、構図ズレ・ポーズ変化・輪郭破綻といった問題が起こりやすくなります。
ControlNet を入れると「形だけ事前に決められる」ため、これらの問題が防げます。
■動作の流れ
1.Preprocessor が輪郭・深度・ポーズなどの形情報を抽出
2.ControlNetモデル がその情報を UNet に伝達
3.UNet が形を維持しながら細部を生成
■要点
・Preprocessor:画像 → 形の特徴(線・深度・骨格)に変換
・ControlNetモデル:その形を生成中の UNet が守れるように伝える
この 「前処理 → 形の翻訳 → 生成へ反映」 が、ControlNetによって “形がブレない画像生成” を実現する根本です。
5.2 まずは全体像をつかむ:モデルの“大分類”で整理する
ControlNetモデル選びで迷わないコツは、まず「分類の基準」を知ることです。個別のモデル名を見る前に、まずは全体像を捉えるための「3つの大きな軸」で整理し、判断の基準を明確にしましょう。
■ControlNetモデルを“3軸”でとらえる
| 分類軸 | どんな違い? | どこで効いてくる? |
|---|---|---|
| ① Checkpoint世代 | SD1.5 / SDXL など、学習元モデルによる違い | 対応する生成モデルに合わせる前提条件 |
| ② モデル設計方針 | 専用モデル / UNIONモデル | 表現の“強さ”や“守備範囲の広さ” に影響 |
| ③ モデルサイズ | full / mid / small / lite | 処理速度や精度、GPU負荷 に関係 |
「どれを使うべきか?」に迷うときは、まずこの3軸で “自分の選択肢の位置” を把握するところから始めましょう。
① Checkpoint世代:対応する世代にあわせて使う
ControlNetは 対応するベースモデルの世代が決まっています。
・SD1.5 世代向け
・SDXL 世代向け
基本的には 使っている生成モデルと同じ世代を選ぶだけでOK。
「前提条件として世代は合わせる必要がある」という点だけ押さえておきましょう。
② モデル設計方針:専用モデル vs UNIONモデル
ControlNetには、特定の機能に特化した「専用モデル」と、複数の機能を1つにまとめた統合型の「UNIONモデル」の2つの設計方針があります。
・専用モデル: CannyやPoseなど、特定の制御に最適化された従来型。
・UNIONモデル: 1つのモデルで複数の制御をこなせる最新の統合型。
次のセクションでそれぞれのメリット・デメリットを比較して見ていきます。
③ モデルサイズ:full / mid / small / lite の違い
同じ設計でも、処理速度や精度のバランスで複数のサイズが提供されることがあります。
・full … 精度優先・負荷大
・mid … バランス型
・small / lite … 軽量・速度優先、精度は抑えめ
まずは mid → full の順で試すのが一般的。
GPU性能や生成速度を調整したいときに、この軸が効いてきます。
■まずは“地図”を持つことが、迷わない第一歩
ここでのポイントは、ControlNetの選択は「3軸」で整理できるという全体像をつかむことです。
世代(1.5 / XL) → 設計方針(専用 / UNION) → サイズ(精度 / 軽量)
このフレームを持っておくだけで、後につづく 「専用 vs UNION」 や 「用途別の選び方」 がスムーズに理解できるようになります。
5.3 選択の分岐点!:専用モデル vs UNIONモデル
モデル選びの最初の壁は「専用か、UNION(統合型)か」という選択です。それぞれに強みと限界があり、用途によって最適解は異なります。本節では、両者の技術的な違いと、具体的な使い分けの基準を整理します。
■専用モデル:一点突破の“職人モデル”
専用モデルは、
特定の入力形式(depth / canny / pose …)に最適化された、従来型のControlNet
言い換えると、
「この情報をこの形で渡したい」 という明確な目的を持つとき、最も 素直に、強く効く のが専用モデルです。
・入力形式に合わせた 高い忠実度
・意図が伝わりやすい(挙動が読みやすい)
・生成の 再現性・安定性が高い
・使い分けが必要(用途が広くない)
・複数の形を同時に扱えない
・モデル数が多く、初心者は迷いやすい
■UNIONモデル:複数入力を“1本にまとめる”新世代モデル
UNIONモデルは、
複数の入力形式を1つのモデルで扱える統合型アプローチ
用途を広くカバーできるため、「とりあえずUNIONから始める」 という選択肢も現実的になりました。
・1つのモデルで複数の入力を扱える
・モデル切り替えの手間が減る
・探索コストが低く、作業スピードが上がる
・専用モデルほど“尖らない”ことがある
・入力の組み合わせ次第で 挙動が読みにくい
・設定次第で逆に崩れやすい(※次章で詳しく)
■どちらが“上位互換”なのか?
端的に言うと、
精度・忠実度・立ち上がりの速さ → 専用モデル
守備範囲・効率・探索性 → UNIONモデル
どちらかが完全上位ではありません。
「作りたい画像とワークフローに合うかどうか」 が判断軸になります。
■特徴比較表(ざっくり判断用)
| 観点 | 専用モデル | UNIONモデル |
|---|---|---|
| 適合範囲 | 狭い(そのぶん強い) | 広い(そのぶん調整必須) |
| 忠実度 | 高い | 中~高(状況依存) |
| 挙動の読みやすさ | 読みやすい | 読みにくい時あり |
| 調整難易度 | 低~中 | 中~高 |
| モデル切替の手間 | 多い | 少ない |
| 初心者向け | 最初は難しい・でも理解しやすい | 動くが調整が難しく“沼りやすい” |
| 最初の一歩 | Depth, Canny などから | UNION1本でもOK(※次章参照) |
■最終的なざっくり判断として
・まずはControlNetを感覚的につかみたい、違いを試しながら探っていきたい → UNIONモデル
・表現や結果を安定させたい・“狙った通り”に近づけたい → 専用モデル
5.4 UNIONモデルを使う前に:注意点と“ハマりがちなポイント”
便利なUNIONモデルには、多機能ゆえの「不透明さ」という落とし穴があります。ここでは、使い始めにハマりがちなポイントと、効率的に使いこなすための具体的な注意点を解説します。
■ハマりポイント①:Preprocessor側の設定を見落とす
UNIONモデルは 入力画像の“前処理の精度”に大きく依存 します。つまり、原因はモデル側ではなく Preprocessor 側 にあるケースが多いです。
例)
・OpenPose の検出が荒れている → 手足が崩れる
・Depth の精度が低い → 影の位置が不自然
・Canny が強すぎ → エッジが濃く残りすぎ
💡 コツ:モデルを変える前に Preprocessor の設定や種類を見直す
■ハマりポイント②:“万能”に見えても不得意はある
UNIONは 「何でも混ぜられる」 けれど、「何でも得意」という意味ではありません。
・得意なところ
・不得意なところ
💡 コツ:“傾向を見る=UNION” / “詰める=専用モデル”
探索と制作で住み分ける と迷いが減ります。
■まとめ
まず UNION で方向性を知る → 仕上げは専用
5.5 迷ったらこう選ぶ:用途別おすすめ構成
何から試せばいいの?
そんなときは “再現したい要素が何か” を基準に選ぶのが一番シンプルです。
失敗しにくい最小構成 をご用意しました。まずはここからスタートしましょう。
▼ とにかく試してみたい・触りたい
| 構成 | 理由 | コツ |
|---|---|---|
| UNIONモデル + Canny | 輪郭だけで制御でき、暴走しにくい。結果が読みやすい | Cannyの閾値は初期値のままでOK |
▼ 写真や人物画像に “形の安定感” がほしい
| 構成 | 理由 | コツ |
|---|---|---|
| UNIONモデル + Depth | 立体・奥行きが入ることで 破綻しづらい | 元画像に陰影があるほど効果的 |
▼ ポーズやアクションを “そのまま再現” したい
| 構成 | 理由 | コツ |
|---|---|---|
| 専用モデル(OpenPose系) + OpenPose | ポーズが最優先なら専用モデルが安定 | 骨格画像が正確だと成功率アップ |
5.5.1 用途別:モデル取得リンク一覧
この章の最後に、用途に応じたモデル取得リンク の一覧をご用意しました。
「まずは使ってみたい」「安定した生成が目的」「特定の形を強く反映したい」など、自分がやりたい方向に合わせて選んでみてください。
※リンク先は HuggingFace サイトです。
■UNION モデル
【SDXL】UNION
https://huggingface.co/xinsir/controlnet-union-sdxl-1.0/tree/main
・diffusion_pytorch_model.safetensors
・diffusion_pytorch_model_promax.safetensors
■SDXL 専用モデル
【SDXL】OpenPose
https://huggingface.co/xinsir/controlnet-openpose-sdxl-1.0/tree/main
・diffusion_pytorch_model.safetensors
・diffusion_pytorch_model_twins.safetensors
【SDXL】Canny
https://huggingface.co/diffusers/controlnet-canny-sdxl-1.0/tree/main
・diffusion_pytorch_model.fp16.safetensors
・diffusion_pytorch_model.safetensors
【SDXL】Depth
https://huggingface.co/xinsir/controlnet-depth-sdxl-1.0/tree/main
・diffusion_pytorch_model.safetensors
※そのままダウンロードすると同じ名前で上書きされてしまう場合がるため、手動でリネームして保存するのが一般的です。
例)diffusion_pytorch_model.safetensors → diffusion_pytorch_sdxl_canny.safetensors
■SDXL 専用モデル(サイズ別)
【SDXL】Canny / OpenPose / Depth など
https://huggingface.co/lllyasviel/sd_control_collection/tree/main
※以下Cannyモデル例
・diffusers_xl_canny_full.safetensors【2.5 GB】
・diffusers_xl_canny_mid.safetensors【545 MB】
・diffusers_xl_canny_small.safetensors【320 MB】
・kohya_controllllite_xl_canny.safetensors【46.2 MB】
など
■SD1.5 専用モデル
【SD1.5】Canny / OpenPose / Depth など
https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/tree/main
・control_v11p_sd15_canny_fp16.safetensors
・control_v11p_sd15_openpose_fp16.safetensors
・control_v11f1p_sd15_depth_fp16.safetensors
など
6.次回予告:ControlNetをもっと活かすために
ここまでで、ControlNetを「導入できる」「動かせる」「選べる」 状態になりました。
形の制御が“どんな仕組みで効いているのか”も、ひと通りつかめたはずです。
次のステップでは、
いよいよ 「使いこなす」「狙いに合わせて操る」 世界へ進みます。
🔎 次回扱う予定の内容
- 複数のControlNetを組み合わせる:
輪郭+ポーズ/立体+線画 など、「どこまで指定すると、どう変わるのか」 を比較しながら扱います。 - 同じ画像で比較して理解する:
Canny / Depth / OpenPose / Lineart / Scribble などを元画像 → Preprocessor結果 → 生成結果 の並びで比較し、“形の受け渡し方” を体感していきます。 - なぜ失敗する?を理解する:
形が崩れる・大きく逸れる・情報が多すぎる —
次回は、こうした “ハマりポイント” を実際の生成例と一緒に 見ながら整理します。
🚀 次のゴール
「なぜその結果になったか」を説明できるようになること
= 狙った形に近づけるための修正が自分でできる状態
ControlNetは、ただ“つなぐ”だけでは 制御しきれません。
しかし “違いを比較しながら調整する” ことを覚えると、画像生成の再現性と手応えが一気に増します。
📌 まとめ
今回は「触れる・動く・選べる」まで。
次回は「比べて、理解して、狙う」へ。
次のステップで、ControlNetが“道具”から“武器”に変わります。
武器にしてぇぜ
コメント